1. 通用爬虫
- Baidu Google Yahoo
2. 聚焦爬虫
- 面向特定主题
1. 网络请求模块
- urllib requests aiohttp
2. 爬虫控制模块
- url队列
3. 信息提取模块
- bs4 xpath 正则
构造http:自由度高、根据需求变化
requests
asyncio-aiohttp
使用框架: 按照特定的模式进行爬取
scrapy
pysider
使用selenium: 基于浏览器模拟用户行为
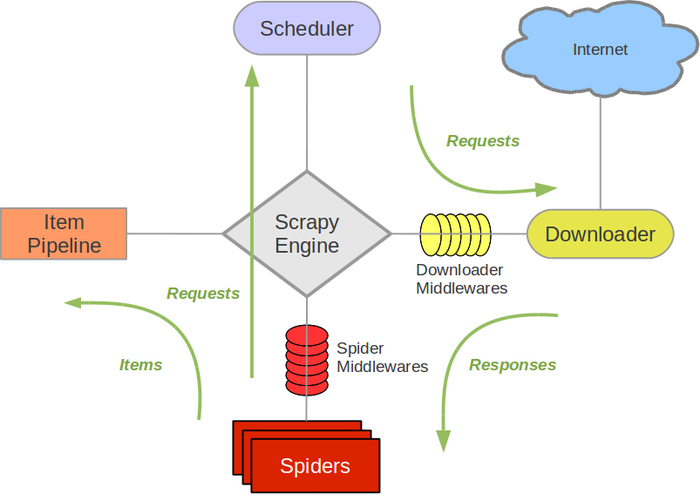
Scrapy Engine:引擎,负责其他组件通信,事件调度触发
Spiders:负责处理Response,提取数据
Scheduler:构造请求队列
Downloader:下载request
Item Pipeline:数据清洗、持久化
---------------------------------------
https://github.com/wxq0309/doubanSpider
import time
def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
time.sleep(sleep_time)
print('OK {}'.format(url))
def main(urls):
for url in urls:
crawl_page(url)
start = time.time()
main(['url_1', 'url_2', 'url_3', 'url_4'])
print(time.time()-start)
-----------------------
crawling url_1
OK url_1
crawling url_2
OK url_2
crawling url_3
OK url_3
crawling url_4
OK url_4
10.032896757125854
import time
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
for url in urls:
await crawl_page(url)
start = time.time()
asyncio.run(main(['url_1', 'url_2', 'url_3', 'url_4']))
print(time.time()-start)
import time
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
tasks = [asyncio.create_task(crawl_page(url)) for url in urls]
for task in tasks:
await task
start = time.time()
asyncio.run(main(['url_1', 'url_2', 'url_3', 'url_4']))
print(time.time()-start)
import time
import asyncio
async def worker_1():
print('worker_1 start')
await asyncio.sleep(1)
print('worker_1 done')
async def worker_2():
print('worker_2 start')
await asyncio.sleep(2)
print('worker_2 done')
async def main():
task1 = asyncio.create_task(worker_1())
task2 = asyncio.create_task(worker_2())
print('before await')
await task1
print('awaited worker_1')
await task2
print('awaited worker_2')
start = time.time()
asyncio.run(main())
print(time.time()-start)
-------------------------
before await
worker_1 start
worker_2 start
worker_1 done
awaited worker_1
worker_2 done
awaited worker_2
2.008479356765747
分析:
asyncio.run(main()),程序进入 main() 函数,事件循环开启;
task1 和 task2 任务被创建,并进入事件循环等待运行;运行到 print,输出 'before await';
await task1 执行,用户选择从当前的主任务中切出,事件调度器开始调度 worker_1;
worker_1 开始运行,运行 print 输出'worker_1 start',然后运行到 await asyncio.sleep(1), 从当前任务切出,事件调度器开始调度 worker_2;
worker_2 开始运行,运行 print 输出 'worker_2 start',然后运行 await asyncio.sleep(2) 从当前任务切出;
以上所有事件的运行时间,都应该在 1ms 到 10ms 之间,甚至可能更短,事件调度器从这个时候开始暂停调度;
一秒钟后,worker_1 的 sleep 完成,事件调度器将控制权重新传给 task_1,输出 'worker_1 done',task_1 完成任务,从事件循环中退出;
await task1 完成,事件调度器将控制器传给主任务,输出 'awaited worker_1',·然后在 await task2 处继续等待;
两秒钟后,worker_2 的 sleep 完成,事件调度器将控制权重新传给 task_2,输出 'worker_2 done',task_2 完成任务,从事件循环中退出;
主任务输出 'awaited worker_2',协程全任务结束,事件循环结束。
对于爬虫使用selenium模拟用户行为,还是采用scrapy之类的框架,或者是使用第三方的requests需要根据业务评估,存在js渲染dom并且反扒严重的可以使用selenium
有大量网站需要爬取,并且爬取规则类似的推荐使用框架
对于反扒严重,各网站规则不同的情况下可以使用requests、aiohttp进行合理构造请求爬取